Managing Workload Identities
The continued shift to cloud computing is causing more software workloads to move to the cloud. Most new enterprise software developed these days are built natively to the cloud. These software workloads, made up of applications, scripts, services and daemons, typically need an identity to authenticate and access resources or communicate with other services. This has resulted in a dramatic increase in “workload identities” in cloud identity systems.
Most cloud identity systems have a good level of maturity when it comes to securing, managing and governing user identities. However, the same level of maturity does not exist for workload identities. The increasing awareness of the damage caused due to security breaches is causing many enterprises to pay closer attention to managing these identities. They are seeking capabilities such as lifecycle management, access governance, secure adaptive access and secrets management.
Digging into the details…
Terminology
First, let’s start with the terminology. There is no consistent terminology in the industry today for these “software identities”. In Azure AD, depending on what they are used for, they are called application identities, managed identities or service principals. Zervice Accounts os another term that shows up in many platforms, including Windows Active Directory. The plethora of names leads to confusing outcomes especially when people sometimes use different terminologies to mean the same thing.
Microsoft is using the term “workload identity” to broadly refer to the identities needed by software workloads. Here are some sample scenarios that need workload identities:
- An application that is able to access Microsoft Graph based on admin or user consent. This access may be either on behalf of the user or app-only mode.
- A Managed identity used by a developer to provision their service with access to an Azure resource such as Azure KeyVault or Azure Storage.
- A Service prinicipal used by a developer to enable CI/CD with GitHub Actions.
“Workload identity” is a term that some industry analysts and product vendors are already using. To put these identities in perspective of the broader landscape of identities, it is useful to look at the taxonomy of all identities in Azure AD.
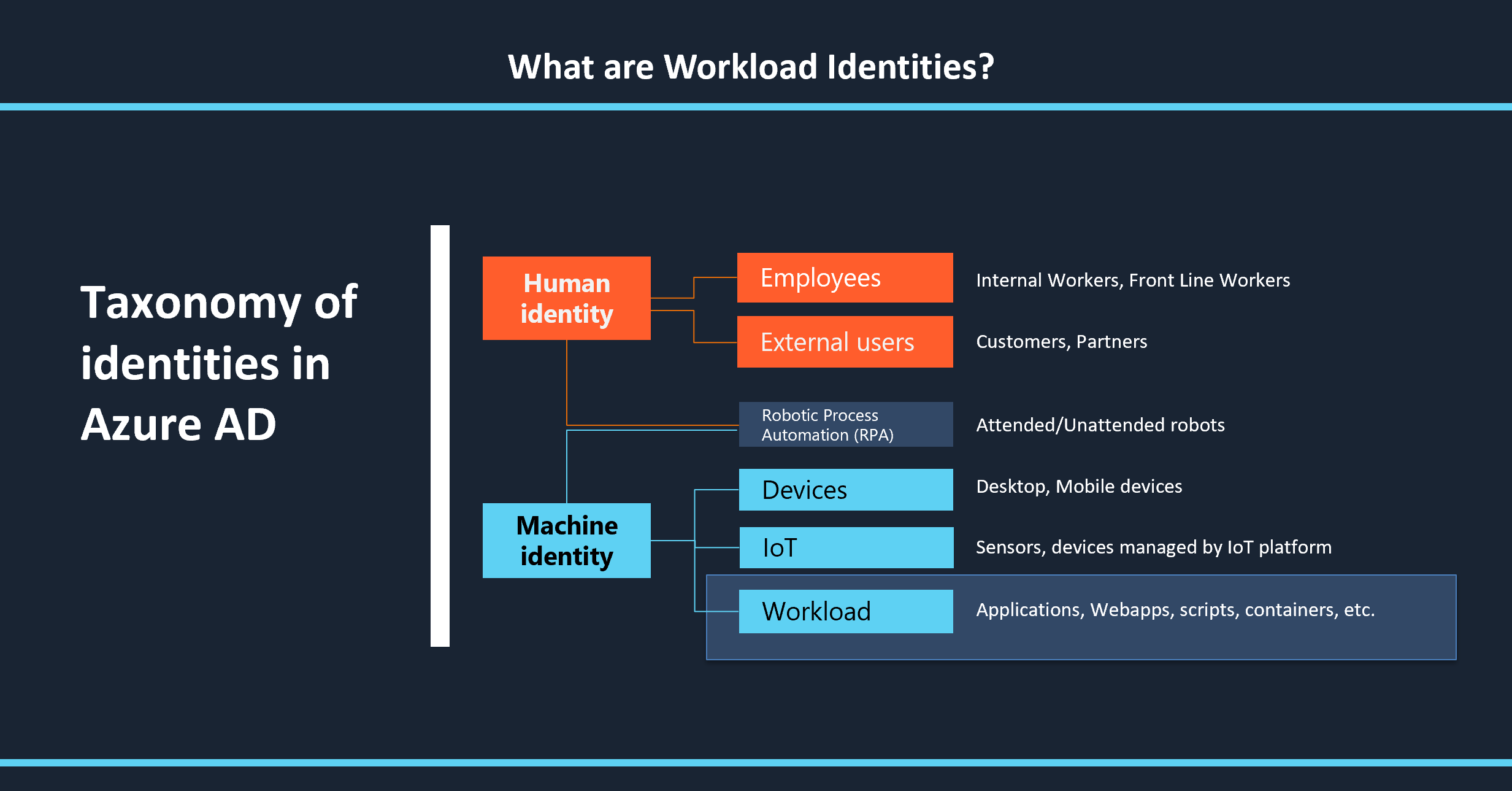
Human Identities
These are the ones we are most familiar with. We use them every day and companies use these identities to provision their employees and Frontline Workers (FLW) with access to things they need. These identities also allow external users, such as business partners or end consumers, to be provisioned with the right level of access.
Machine Identities (or non-human identities).
Machine identity is a term that is used by some industry analysts as well as product vendors to cover all the scenarios for non-human identities. We can classify them further into four broad categories. Over time, it is likely that these categories overlap or even converge.
-
Mobile or Desktop Devices: Devices that we carry with us, either mobile or desktop, need an identity. In Azure AD, this identity is used to enable scenarios such as conditional access requiring a compliant device.
-
Internet of Things (IoT): These devices typically act on their own, unlike a handheld device or a desktop.
-
Workload Identities: These are the identities referred to in this blog. They represent identities needed by applications, services and scripts to authenticate and access resources.
-
Robotic Process Automation (RPA) : RPA is a relatively new trend where human-based processes are being automated. Some of these scenarios end up needing a user identity, primarily to deal with restrictions in software licensing. Other scenarios may lend themselves to use of the different types of machine identities.
So, what are some issues customers face with workload identities?
As the number of workload identities increase, identity administrators are starting to wonder how to manage their growing number. The regular spate of security breaches is causing a heightened awareness of the need to secure and govern these identities. Developers checking in the credentials/secrets for these identities in their code into their GitHub repos has been a common weakness that hackers are exploiting. The most infamous of these exploits was with Uber several years ago. This is causing IT administrators to ask all the right questions: how do we avoid compromised workload identities trying to access our systems? Why can’t we use conditional access policies as we do for users? What do we need to do to clean up these identities when they are no longer in use?
Workload identities cannot be managed in the same ways we manage user identities. Let’s look at some of the unique differences to see why we need specialized capabilities for these identities.
No joiner/mover/leaver process.
User identities have a clear process, typically called joiner/mover/leaver, that is rooted in the HR system. When a user joins the company, they are added to the HR system which results in them being provisioned in the identity system. Using the information in the HR system, the user profile can be enriched with attributes such as their team and their role. This allows the user to be provisioned the right access needed for their job, for example by dynamically adding them to groups based on these attributes. When the user moves to a different team or role, they are automatically removed from the original group and placed in a different group, gaining access to new resources while losing access to the old ones.
Workload identities don’t have a similar formal process that we can rely on. They get created by someone who deploys the application or service and are generally forgotten after that. It is usually difficult to figure out if a workload identity is still in use, and what it has access to. The person who created this identity may have forgotten why they created this, may have changed teams or even left the company. So then how do you manage the lifecycle of these identities? In most cases, this ambiguity results in them remaining in the system forever.
Need to be provisioned with credentials or secrets.
Unlike users who can typically show gestures or biometrics to prove thier identity, workload identities need to be provided their credentials to authenticate and get access to resources. Careful attention needs to be paid to manage these secrets. Many organizations dont have strong guidance in this area. It is up to individual developers or devops team to figure this out. The rotation of secrets tends to be especially challenging. This part part is hard for most folks to automate. It tends to be done rarely and manually. Given this challenge, customers need better tools to ensure these credentials are stored securely and rotated regularly.
Multiple identities with fine-grained access to a variety of resources
A single workload may be configured with multiple workload identities. For example, the application identity may be used to access Microsoft Graph. And individual services within the application may have their own identities, one of which may be provisioned to access Azure KeyVault and the other with access to Azure Storage. Given this characteristic, customers need ways to check what an identity has access to and how long that access should remain.
Improving the management of these identities
We hear from customers and industry analysts that this is a space that is fraught with problems primarily because there are no good solutions to tackle these issues. While niche tools do exist for things such as secret management and privileged access management, they solve a very small subset of the problem space. Customers will benefit from better ways to govern, secure and manage these identities. Here are thoughts on the core capabilities needed to address this area comprehensively.
Lifecycle management
The most important part of managing the lifecycle of these identities is to capture the meta-data on who created it and why it was created. This information needs to be automatically updated even as employees move teams or leave the organization. In addition, it is necessary to complement this information with data on the activity from that identity, such as when it last authenticated.
Access governance
The lack of a formal process such as joiner/mover/leaver makes it challenging to govern the access granted to these identities. Customers need reports on all the resources an identity can access, along with tips on which access can be safely removed. They need capabilities such as access reviews, where the owner of the identity is required to assess that the identity and its access assignments are still needed.
Secure adaptive access
Customers need capabilities that allow them to assume breach and plan accordingly. Conditional access policies play an important role here, for example only allow a workload identity to authenticate from within their company’s network. With identity protection, we can analyze the access pattern of the past and check for anomalies in the pattern. This can then generate a risk score for reporting or even feed into the conditional access policies to block access when the risk is deemed high.
Secrets management
It is best to avoid secrets in the first place if possible, and towards that, Microsoft has made significant investments in “Managed identities” for Azure. The credentials for these identities are managed by the Azure platform, storing them securely and rotating regularly. While this will avoid secrets in some scenarios, there are others where a secret is still necessary. So it becomes important to invest in vaulting solutions such as Azure KeyVault or other tools which can help with rotating these credentials and storing them securely.
In conclusion
Microsoft recently announced the public preview of access reviews for service principals. Expect to see more capabilities in this area for customers to better manage, govern and secure workload identities.
Comments/feedback/questions? DM me on twitter